Credit: Me, Deep Learning for Computer Vision, National Taiwan University
What I've Done:
- Accelerated style-conditioned multimodal diffusion training by 44% via Image Prompt Adapters and ControlNet
- Enhanced PEFT/LoRA-based model fidelity by introducing structural separation loss to resolve attribute leakage
- Outperformed SOTA LoRA-based diffusion by 1.4% on CLIP-I and 2.2% on CLIP-T in multi-concept text-to-image personalization
Motivation: Multi-Concept Text-to-Image Generation
Text-to-image diffusion models have revolutionized image generation, but existing methods struggle with
multi-concept personalization where multiple distinct concepts need to be combined while maintaining
individual characteristics and spatial relationships. Current approaches like Custom Diffusion and LoRA
often suffer from concept interference, where one concept dominates others, or fail to maintain
consistent style across different concepts in a single generated image.
Our objective is to develop an efficient framework that can seamlessly combine multiple personalized
concepts while preserving their individual characteristics and applying consistent stylistic transformations.
A Novel Framework for Multi-Concept Personalization
Our framework addresses the challenges of multi-concept personalization through a carefully designed two-stage approach. The first stage focuses on concept fusion using the Concept Conductor framework, where ED-LoRAs are trained separately for each concept and combined during inference. The second stage applies style transfer using IP-Adapter while maintaining structural integrity through ControlNet, ensuring that the generated images not only contain the desired concepts but also exhibit consistent artistic styles.
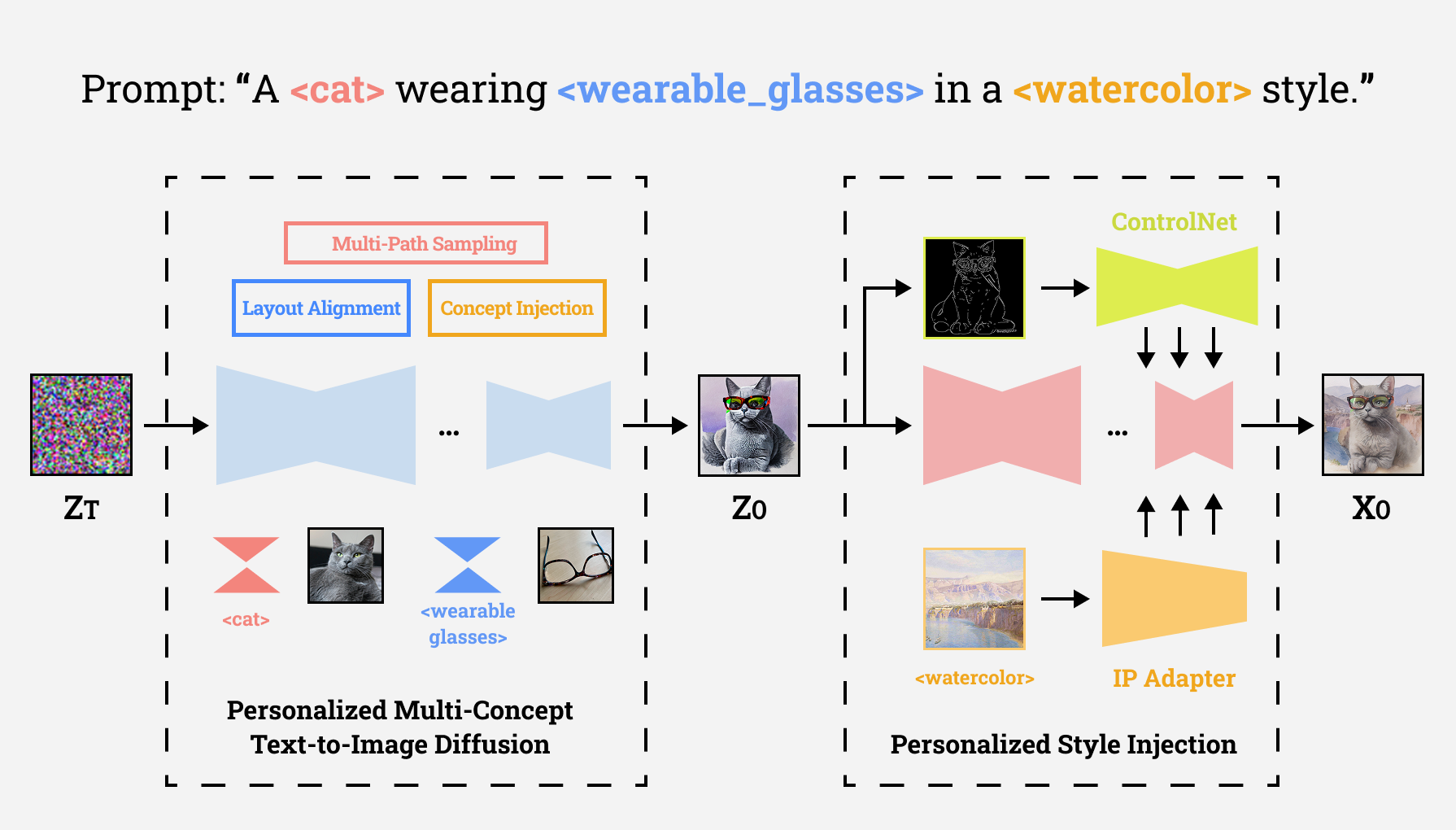
Our Two-Stage Diffusion Framework for Multi-Concept Personalization
The key innovation lies in our attention separation loss, which ensures that different concepts maintain their spatial boundaries and don't interfere with each other during the generation process. This is achieved by manipulating attention layers in the diffusion model using masks obtained from the Segment Anything Model (SAM), allowing for precise control over concept placement and interaction.
Our experimental results demonstrate significant improvements over existing methods. The framework successfully generates images with multiple personalized concepts while maintaining high visual fidelity and consistent style representation. The attention separation mechanism effectively prevents concept bleeding and ensures that each concept retains its distinctive characteristics within the final generated image.

Visualization of Personalized Styling Process
Technical Details
The implementation leverages state-of-the-art models including Stable Diffusion v1.5 as the base architecture, DALL-E 3 for reference image generation, and Segment Anything Model (SAM) for precise mask extraction. The integration of IP-Adapter enables effective style transfer, while ControlNet ensures structural consistency throughout the generation process. This comprehensive approach addresses the technical challenges of multi-concept personalization while maintaining computational efficiency and generation quality.



